
Jak zbudować asystenta AI dla firmy? (Poradnik krok po kroku)
Większość asystentów AI, którymi chwalą się dzisiaj firmy, to tak naprawdę bezużyteczne zabawki do generowania wierszyków. Właściciele wrzucają do nich chaotyczne PDF-y z ofertą, odpalają wklejony z internetu prompt i dziwią się, że system po godzinie zaczyna zmyślać cenniki przed klientem. Bot głupieje, bo dostaje informacyjne śmieci. W tym wpisie rozłożę operacyjny proces budowy bota na części pierwsze.
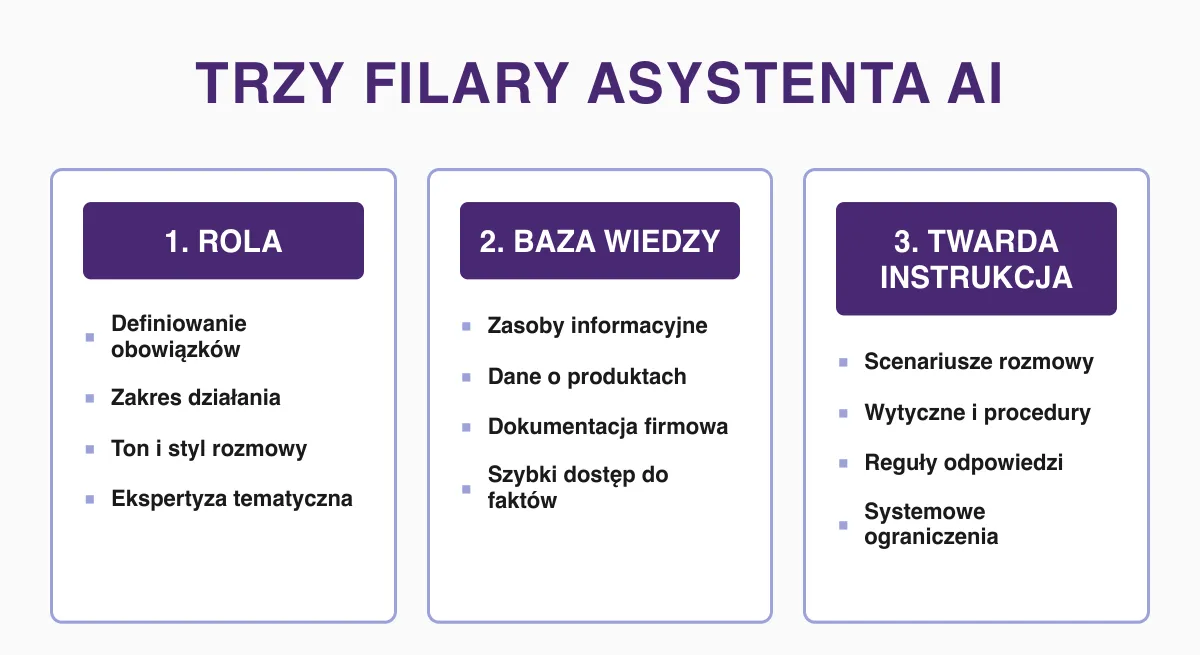
Zanim przejdziemy do konkretów, musimy zmienić myślenie. Zbudowanie asystenta to nie jest napisanie jednego, przydługiego promptu. To budowa całego systemu. Tworzenie skutecznego bota sprowadza się do trzech nierozerwalnych filarów: stworzenia ram samego asystenta (jego roli), zbudowania czystego kontekstu (bazy wiedzy) oraz dodania twardej instrukcji. Tylko takie systemowe podejście działa. Pokażę Ci, jak to wdrożyć u siebie.
Kluczowe wnioski na początek (BLUF)
- Zasada jednego zadania: Asystent musi rozwiązywać jedno, skrajnie wąskie gardło. Kombajny do wszystkiego zawsze w końcu głupieją.
- Higiena danych: Zero ładnych PDF-ów. Modele karmi się czystym, wyczesanym tekstem z wyraźnymi nagłówkami. Zły tekst na wejściu to zły tekst na wyjściu.
- Twarde granice: Instrukcja systemowa to nie prośba. To twardy zakaz zmyślania i halucynowania poza wgraną bazą.
Zanim zaczniesz – kubeł zimnej wody na temat asystentów AI
Zewsząd słyszysz, że sztuczna inteligencja zautomatyzuje Twoją firmę, napisze za Ciebie maile, obsłuży klientów i jeszcze zaparzy kawę. To ładne bajki wyjęte prosto z prezentacji sprzedażowych z Instagrama. Zanim w ogóle otworzysz jakiekolwiek narzędzie do stworzenia asystenta, musimy ustalić jedną rzecz. Bot sam w sobie jest głupi. Zrobi dokładnie to, co mu każesz, bazując wyłącznie na tym, co mu podasz na tacy.
Jeśli liczysz, że asystent wejdzie do Twojej firmy i w magiczny sposób sam domyśli się, jak wyglądają Wasze procesy i zasady – grubo się przeliczysz.
Dlaczego większość firmowych asystentów to bezużyteczne zabawki?
Firmy masowo zachłysnęły się wizją sztucznej inteligencji, próbując budować kombajny do wszystkiego. Właściciel siada przed ChatGPT, wrzuca mu ogólnikową instrukcję typu: „Jesteś asystentem Targetly. Masz pisać maile sprzedażowe, generować posty na LinkedIn, odpisywać na zgłoszenia rekrutacyjne i analizować umowy, a po tygodniu łapiesz się za głowę, bo bot zaczyna odpisywać klientom językiem prosto wyciągniętym z rekrutacji 😉
Problem w tym, że modele językowe to nie magiczna skrzynka, która potrafi trzymać w pamięci pięć różnych procesów operacyjnych na raz. Im szerszy zakres obowiązków mu zadasz, tym szybciej straci on kontekst. Zacznie używać sztywnego języka przeznaczonego do postów PR-owych w bezpośrednich mailach do nieco zdegustowanych klientów.
Zamiast przyspieszać pracę, stworzysz potwora, którego odpowiedzi Twoi pracownicy będą musieli ręcznie redagować, zerkając ciągle w prawdziwe dokumenty. A to zajmie im więcej czasu, niż gdyby napisali tę odpowiedź od zera. W końcu ktoś uderzy w stół i zacznie robić tak jak robił dotychczas, czyli całkowicie ręcznie.
Czym NIE JEST wirtualny asystent w 2026 roku?
Szybko zbijmy kolejny mit o AI. Twój nowy asystent nie jest niezależnym pracownikiem, któremu rzucisz zadanie przez ramię i pójdziesz na kawę. Nie jest też wyrocznią, która wejdzie w systemy CRM i magicznie połączy kropki z 15 różnych baz danych bez Twojego prowadzenia za rękę.
Jeśli do tej pory traktowałeś sztuczną inteligencję jak człowieka, który w razie wątpliwości sam dopyta o szczegóły, to przestań. Dzisiejsze modele to po prostu potężne filtry do układania tekstu w ustrukturyzowane ramy.
Traktuj asystenta jak wysoce zaawansowany kalkulator tekstowy. Ma wejście (Twoja baza wiedzy i polecenie), sztywny proces (instrukcja systemowa) i wyjście (gotowy szkic). Maszyna nie domyśla się intencji, nie podejmuje samodzielnych decyzji biznesowych i na pewno nie posprząta bałaganu wynikającego z tego, że w Twojej firmie panuje informacyjny chaos.
Wdrażanie asystenta AI bez przemyślanego, twardego procesu biznesowego jest jak kupno sportowego samochodu dla kogoś bez prawa jazdy. System będzie na początku robił świetne wrażenie i ryczał silnikiem, ale na pierwszym poważnym, merytorycznym zakręcie rozbijesz go na drzewie.
Custom GPTs, Claude czy Gemini? Narzędzie nie ma znaczenia
Wielu ekspertów będzie Ci wciskać, że wybór odpowiedniego środowiska to kluczowa decyzja, od której zależy życie lub śmierć Twojego biznesu. To bzdura. Prawda jest taka, że na ten moment różnice między narzędziami (ChatGPT, Claude, Gemini) są na tyle małe, że powinieneś po prostu wybrać to, z którym pracuje Ci się najwygodniej.
Wszystkie czołowe modele oferują własne zamknięte ekosystemy (w płatnych planach pro), w których wgrywasz bazę plików, definiujesz instrukcję systemową i ograniczasz halucynacje. Pogoń za mikroskopijnymi różnicami w jakości tekstu mija się z celem, bo wszystkie z nich radzą sobie z czytaniem tekstu i formatowaniem na bardzo podobnym, ultrawysokim poziomie.
Głównym kryterium wyboru nie powinien być więc sam model, ale ekosystem, w którym już pracujesz. Oczywiście można bawić się w podpinanie innych modeli, ale to kosztuje dodatkowy czas.
Ja na co dzień korzystam z pełnego pakietu Google Workspace, dlatego moim naturalnym wyborem stało się Gemini. Mam tam natywny, wbudowany dostęp do wszystkich swoich dokumentów w Google Docs, prezentacji i dysków współdzielonych bez robienia skomplikowanych integracji. Jeśli Ty siedzisz w ekosystemie Microsoftu albo wolisz ułożenie folderów w Claude – weź Claude. To ma po prostu z Tobą rezonować.
Krok 1: Zlokalizuj jedno konkretne wąskie gardło
Masz już wybrane środowisko operacyjne (GPT, Claude lub Gemini). Pierwszym błędem, jaki popełnia 90% firm na tym etapie, jest natychmiastowe rzucenie się do tworzenia Głównego Asystenta Firmy, który ma uratować cały biznes z dnia na dzień. Niestety, wdrażanie sztucznej inteligencji to nie jest podpięcie nowej drukarki w biurze – bez ścisłego określenia, jaki konkretnie i mierzalny proces biznesowy chcesz oddelegować, skończysz z kolejnym irytującym narzędziem, którego i tak nikt w zespole nie używa.
Dlaczego asystent „do wszystkiego” to proszenie się o kłopoty?
Zasada budowania własnego bota jest prosta – asystent, który ma robić rzekomo wszystko, w rzeczywistości nie potrafi zrobić niczego dobrze.
Wyobraź sobie, że zatrudniasz nową osobę z ulicy bez żadnego onboardingu. Pierwszego dnia sadzasz ją przy biurku i mówisz: „Słuchaj, od dzisiaj prowadzisz naszą księgowość. Albo odpisujesz na techniczne maile wsparcia. Robisz research konkurencji i negocjujesz umowy najmu”. Co się stanie? Pracownik zaleje się potem po dwóch godzinach, a każda z tych rzeczy będzie zrobiona fatalnie. Ewentualnie dostaniesz wypowiedzenie na twarz.
Dokładnie to samo robisz modelowi językowemu, kiedy ładujesz w jego bazę wiedzy całą historię firmy na raz i oczekujesz, że on sam się domyśli, czego akurat od niego wymagasz. Im więcej skrajnie różnych danych i procedur w niego wrzucisz, tym bardziej rozwadniasz jego możliwości analityczne (to zjawisko nazywa się lost in the middle, gdzie model gubi kluczowe fakty w natłoku tekstu). Asystent zacznie mieszać sztywne procedury reklamacyjne z luźnymi ofertami promocyjnymi dla nowych klientów.
Sukces polega na atomizacji. Zlokalizuj jeden, powtarzalny proces, którego fizycznie nienawidzisz robić, i zbuduj asystenta tylko do tego jednego zadania.
Jeśli chcesz szybko upewnić się, że wybrane zadanie jest wystarczająco wąskie dla bota, zadaj sobie jedno twarde pytanie: „Czy byłbym w stanie spisać tę całą procedurę dla nowego pracownika z ulicy, mieszcząc się na jednej kartce A4?”. Jeśli tak – to jest idealny materiał na niezawodnego asystenta operacyjnego.
Praktyczne przykłady z życia (zamiast jednego asystenta, stwórz pięciu)
Żeby lepiej to zobrazować, rzućmy okiem, jak to wygląda na operacyjnie. Zamiast budować jednego, przerośniętego „Asystenta Działu Handlowego” lub „Asystenta e-commerce”, powinieneś rozbić zadania i stworzyć wyspecjalizowane mikro-narzędzia.
- Skaner dokumentacji przetargowej (B2B): wgrywasz mu tylko twarde, techniczne specyfikacje Waszych produktów i bazę projektów z ostatnich dwóch lat. Cel? Asystent ma skanować 100-stronicowe zapytania ofertowe (RFP) z publicznych zapytań i wypluwać czystą tabelę z punktami, których Wasza firma w tym przetargu nie jest w stanie dowieźć.
- Asystent obsługi reklamacji (B2C): wgrywasz mu wyłącznie regulamin sklepu, zasady gwarancji i FAQ. Zdenerwowany klient wysyła chaotycznego maila. Twój pracownik BOK-u wkleja jego treść asystentowi, a ten w trzy sekundy układa ustrukturyzowaną, spokojną odpowiedź, powołując się na konkretny punkt regulaminu i generując odpowiednie linki do zwrotu.
- Transkrypcja rozmów (B2B): wgrywasz mu schemat kwalifikacji leada (np. ICP). Po każdym callu sprzedażowym handlowiec wrzuca mu surową transkrypcję z Google Meet. Bot odrzuca pogaduszki o pogodzie i układa idealną notatkę z kluczowymi danymi – gotową do wklejenia w CRM.
- Personalizator kampanii e-mailowych (B2C): wgrywasz asystentowi plik z nową kolekcją i jej cechami. Następnie podrzucasz mu opisy trzech różnych grup docelowych (np. „stałe klientki premium” vs „łowcy promocji”). Bot zamiast jednego, generycznego newslettera generuje trzy zupełnie różne maile dopasowane do języka i potrzeb danego segmentu.
- Asystent wdrożeniowy (HR): ładujesz w niego firmowy playbook, dokumenty onboardingowe dla nowych pracowników. Zamiast odrywać HR od pracy setką powtarzających się pytań o to, gdzie jest wniosek o urlop czy kiedy przyjeżdża dostawa owoców (XD), nowy pracownik zyskuje możliwość dosłownej rozmowy z nudnymi procedurami.
Tak ściśle zdefiniowane wąskie gardła i odcięcie bota od zbędnych informacji gwarantują, że AI nie będzie halucynować (aż tak), a Ty realnie odzyskasz czas na coś bardziej produktywnego.
Krok 2: Przygotuj surową bazę wiedzy (serce asystenta)
Masz już zlokalizowane wąskie gardło i wybrane narzędzie. Czas na najważniejszy, najbardziej analityczny etap całego procesu, na którym wykłada się przytłaczająca większość początkujących: przygotowanie bazy wiedzy (często nazywanej w panelach modeli jako Knowledge Base). To fizyczna, odseparowana przestrzeń, do której wgrywasz asystentowi pliki stanowiące absolutny fundament jego działania.
Zrozumienie koncepcji bazy wiedzy to punkt zwrotny w pracy z AI. Kiedy odpalasz standardowego, czystego ChatGPT, rozmawiasz z modelem, który przeczytał po trochu cały internet. Brzmi to imponująco w artykułach prasowych, ale dla Ciebie – jako eksperta lub właściciela firmy – jest kompletnie bezużyteczne. Model wie doskonale, czym ogólnie jest kampania sprzedażowa, ale nie ma zielonego pojęcia, jak wygląda Twoja kampania, jakie masz wynegocjowane stawki z podwykonawcami i jak brzmi Twój autorski proces onboardingu klienta. Czysty model to po prostu encyklopedia, a Ty nie potrzebujesz encyklopedii, tylko pracownika.
Baza wiedzy działa jak odcięcie asystenta od wiedzy ogólnej. Wgrywając tam konkretne dokumenty – zbiory trudnych pytań od klientów (FAQ), historyczne kosztorysy projektów, procedury wdrożeniowe czy zbiór wymagań – wymuszasz, by przestał halucynować, zgadywać i opierać się na wyuczonych z internetu frazesach. Zamiast tego, zaczyna przetwarzać zweryfikowane przez Ciebie fakty z Twojego firmowego podwórka. Dopiero wtedy wirtualny asystent staje się powtarzalnym narzędziem operacyjnym, a nie zabawką. Wszystko będzie odbijać od Twojego firmowego kontekstu.
Garbage in, garbage out (złota zasada sztucznej inteligencji)
W świecie analityki danych od dziesięcioleci funkcjonuje bezlitosna zasada GIGO – Garbage in, garbage out. W brutalnym tłumaczeniu na nasze, jeśli wgrasz do asystenta informacyjne śmieci, w odpowiedzi otrzymasz z powrotem śmieci.
Większość przedsiębiorców kompletnie bagatelizuje ten etap. Po prostu łapią dziesięć przypadkowych, niesformatowanych PDF-ów ze swojego dysku – w tym skrzywione skany z drukarki, rozjechane prezentacje czy umowy z logotypami wciśniętymi na każdej stronie – i ładują je prosto w czat. Towarzyszy temu naiwna nadzieja, że algorytmy „same sobie to jakoś poukładają”.
Otóż, nie poukładają. Kiedy LLMy dostaje brudny tekst, w którym merytoryczne nagłówki zlewają się ze stopkami prawnymi, a tabele cennikowe są odczytywane jako jeden ciąg losowych wyrazów, jej zdolność do logicznego wnioskowania spada do zera.
Zamiast budować precyzyjne narzędzie operacyjne, świadomie zasilasz model chaosem. W takiej sytuacji bot nie potrafi odróżnić głównej usługi od notatki na marginesie. Zanim w ogóle pomyślisz o wrzuceniu jakiegokolwiek pliku do bazy wiedzy, musisz go przygotować, wchodząc do świata czystego tekstu.
Gdybym miał Ci coś doradzić na czerwiec 2026 roku to wróciłbym do cholernych podstaw, czyli nie generować kontekstu dla AI z AI. Tylko usiąść jednego, pięknego dnia i ręcznie, samemu posegregować Twoją wiedzę i przygotować dla LLMa soczysty dokument, pełen realnie sprawdzonej i przeczytanej wiedzy, którą skrzętnie przygotowałeś/aś.
Jak sformatować dokumenty dla AI? (Zapomnij o pięknym designie)
Podstawowy błąd przy tworzeniu bazy wiedzy to myślenie kategoriami wizualnymi. Dla sztucznej inteligencji Twój piękny, graficznie dopieszczony PDF to analityczny koszmar, w szczególności przygotowywany raz w Photoshopie, raz w Illustratorze, a raz to w ogóle w Photopea.
Aby asystent działał dobrze, musisz wyrzucić do śmieci estetykę i wejść w format czysto tekstowy. Najlepszym, najbardziej zrozumiałym formatem dla algorytmów w 2026 roku nie są kolorowe pliki Worda czy skany PDF, a zwykły format Markdown (.md) lub czyste pliki tekstowe (.txt).
Zanim wgrasz cokolwiek do bazy, musisz to nieco obrobić:
- Wyrzuć stopki i ozdobniki: usuń wszystko, co nie jest twardą informacją (np. powtarzające się numery stron, logotypy na marginesach). Modele czytają tekst ciurkiem – stopka prawna wklejona w środku zdania po prostu niszczy zdanie.
- Strukturyzuj tekst nagłówkami: modele nie widzą, że coś pogrubiłeś (chyba, że użyjesz do tego znaczników markdown) i zrobiłeś czerwoną czcionką. Rozumieją za to twardą strukturę. Używaj wyraźnej hierarchii nagłówków (H1, H2, H3), by pokazać maszynie, co jest najważniejsze, a co stanowi wątek poboczny.
- Tabele to analityczna pułapka: skomplikowane tabele (np. z połączonymi komórkami) po konwersji wewnątrz modelu stają się niezrozumiałą zupą wyrazów. Znacznie bezpieczniej jest przerobić je na płaskie listy z wypunktowaniami.
Stworzenie czystego pliku tekstowego potrafi zająć wielokrotnie więcej czasu niż samo wyklikanie asystenta w panelu. Ale to właśnie ta żmudna i niewdzięczna praca odróżnia zabawkowe boty od realnych asystentów.
Limity kontekstu, czyli dlaczego asystent nagle głupieje
Kolejnym błędem podczas budowania bazy wiedzy jest zignorowanie limitów okna kontekstowego (Context Window). Tłumacząc najprościej, to jest fizyczna pamięć krótkotrwała Twojego asystenta.
Każdy model ma twardy limit ilości tekstu, który jest w stanie jednocześnie przeanalizować i utrzymać w głowie podczas jednego zadania. Jeśli wgrasz do bazy pięć podręczników, a model przekroczy swój limit, zacznie zapominać to, co było na samym początku dokumentów. Dokładnie tak samo, jak handlowiec zmuszony do przeczytania na jednym wdechu dwustu stron specyfikacji technicznej na wczoraj.
Dlatego złotą zasadą jest skrajny minimalizm informacyjny. Nie ładuj asystentowi całego, 40-stronicowego regulaminu sklepu, jeśli jego jedynym zadaniem jest kategoryzacja zapytań o koszty dostawy. Wytnij tylko i wyłącznie sekcję o cenniku wysyłek i wgraj ją jako mały, leciutki plik tekstowy. Im mniej zbędnego szumu musi analizować algorytm, tym szybszą i celniejszą odpowiedź dostaniesz na końcu.
Krok 3: Instrukcja systemowa (mózg i twarde zasady gry)
Masz już precyzyjnie zlokalizowane zadanie operacyjne i czystą, bezbłędnie sformatowaną bazę wiedzy. Trzecim i ostatnim elementem układanki konstrukcyjnej jest System Instructions (Instrukcja Systemowa). To to duże pole tekstowe w kreatorze bota (niezależnie od tego, czy używasz OpenAI, czy Claude), w którym wpisujesz algorytmowi zasady, jakimi ma się kierować.
To absolutnie nie jest miejsce na zwykły prompt typu „Jesteś ekspertem, napisz mi fajnego maila”. Instrukcja systemowa to regulamin pracy dla podwładnego. To tutaj z precyzją definiujesz jego rolę, ton wypowiedzi, proces myślowy i – co najważniejsze – to, czego mu bezwzględnie robić NIE WOLNO.
Bez rygorystycznej instrukcji systemowej, asystent szybko zignoruje wgraną bazę wiedzy i zacznie wracać do swoich fabrycznych, grzecznych nawyków, serwując Ci odpowiedzi pełne marketingowych bzdur i sztywnego języka.
Jak zbudować skuteczną instrukcję? (Zamiast rzucać frazesami)
Dobra instrukcja systemowa przypomina twardy algorytm, a nie luźną notatkę do pracownika. Zapomnij o pisaniu życzeniowych zdań typu „Bądź miły, profesjonalny i pomocny”. Sztuczna inteligencja nie rozumie „bycia miłym” – potrzebuje absolutnie konkretnych ram i jasnego łańcucha przyczynowo-skutkowego.
Najlepszą i sprawdzoną metodą na stworzenie instrukcji jest podzielenie jej na sztywne bloki zadaniowe:
- Tożsamość i rola: zdefiniuj od razu, kim jest asystent. Nie pisz „jesteś ekspertem”. Napisz: „Jesteś analitykiem działu wsparcia B2B. Twoim absolutnie jedynym zadaniem jest weryfikacja zapytań ofertowych pod kątem naszej rentowności”.
- Kontekst wejściowy: określ, co fizycznie będzie do niego wpadać (np. „Będziesz otrzymywał nieuporządkowane, surowe transkrypcje ze spotkań handlowych na Google Meet”).
- Kroki operacyjne (procedura): rozpisz dokładnie punkt po punkcie, co ma zrobić. Nie używaj ogólników typu „zrób z tego fajną notatkę”. Napisz: „Krok 1: Wypisz ból klienta. Krok 2: Znajdź kwotę budżetu. Krok 3: Zestaw ten budżet z naszym cennikiem bazowym. Krok 4: Jeśli budżet jest za niski, dodaj na końcu tag [ODRZUCAMY]”.
- Format wyjściowy: Zmuś asystenta do sztywnego ustandaryzowania odpowiedzi. Jeśli ma wypluwać tabelę, powiedz mu, żeby to była wyłącznie tabela, bez żadnego dodawania na końcu „Czy mogę w czymś jeszcze pomóc?”.
Zasada jest jedna: im bardziej techniczny, suchy i proceduralny język zastosujesz w tej sekcji, tym mniejsza szansa na to, że model poczuje wenę i zacznie improwizować.
Guardrails, czyli jak zablokować modelowi pole do halucynacji
Ostatnim i kluczowym elementem w System Instructions jest zdefiniowanie tzw. Guardrails (barier ochronnych). Modele AI z natury mają tendencję do usilnego pomagania za wszelką cenę. Jeśli pracownik zapyta bota HR-owego o to, jak najłatwiej nagiąć procedurę zgłaszania L4, model pozbawiony twardych barier może zacząć radośnie generować kreatywne rozwiązania z internetu.
Dlatego w każdej instrukcji na samym końcu musisz dodać zasady negatywne. Czego asystent robić nie może pod żadnym pozorem?
- „NIE WOLNO Ci odpowiadać na pytania wykraczające poza wgraną bazę wiedzy.”
- „Jeśli w plikach nie ma jasnej odpowiedzi na zadane pytanie, Twoją jedyną dopuszczalną odpowiedzią jest: 'Brak takich danych w mojej bazie. Skontaktuj się z przełożonym’.”
- „ZABRANIAM Ci generowania jakichkolwiek własnych opinii, rekomendacji i porad, które nie wynikają dosłownie z dostarczonych dokumentów.”
Brzmi brutalnie i korporacyjnie? I o to chodzi. To właśnie te bariery fizycznie odcinają model od mocnego halucynowania i sprawiają, że asystent staje się bezpiecznym, zaufanym weryfikatorem danych, a nie uśmiechniętym bajkopisarzem. Czasem i tak poleci spontanicznie, ale na pewno mniej niż zrobiłby to bez barier ochronnych.
Krok 4: Testowanie i żmudna pętla feedbacku
Zlokalizowałeś wąskie gardło, zbudowałeś wyczyszczoną bazę wiedzy, napisałeś twardą instrukcję systemową i właśnie wklejasz w okno czatu pierwsze, testowe zapytanie. Teraz następuje zderzenie z twardą rzeczywistością. Zbudowanie asystenta to nie jest jednorazowy strzał po którym idziesz na kawę, a raczej żmudny proces wyłapywania luk w swoim własnym rozumowaniu.
Twoja pierwsza wersja bota jest głupia (i to jest absolutnie normalne)
Największym zabójcą projektów AI w firmach jest nierealne oczekiwanie, że asystent będzie działał idealnie od razu po wciśnięciu przycisku „Zapisz”. Zbudowanie dobrego, operacyjnego bota to nie jest mały task, który odhaczasz na liście w jedno popołudnie i o nim zapominasz. Pierwsza wersja, którą wypuścisz na swoje firmowe dane, zazwyczaj będzie mocno głupia – i to w sposób, który może Cię skrajnie zirytować.
W marketingu zderzenie czystego algorytmu z realnym światem biznesu bywa, mówiąc szczerze, brutalne. Może się nagle okazać, że asystent zinterpretował Twoją rygorystyczną instrukcję systemową aż nazbyt dosłownie. W efekcie zacznie z automatu odrzucać rentowne, świetne zapytania ofertowe, bo uzna, że w mailu od klienta zabrakło jednej, sztywnej danej z Twoich wymogów. Innym razem bot HR-owy może wpaść w niekończącą się pętlę przepraszania pracownika, generując długie eseje współczucia zamiast twardo wskazać link do wniosku urlopowego.
Zamiast rzucać myszką w monitor i poddawać się z myślą, że ten cały AI bullshit jednak u nas nie działa, musisz zaakceptować ten etap. Modele językowe to potężne narzędzia, ale kompletnie pozbawione ludzkiego wyczucia sytuacji. Twój wirtualny pracownik wręcz musi wyłożyć się na pierwszych, testowych danych, żebyś Ty mógł na własne oczy zobaczyć, gdzie zostawiłeś/aś mu zbyt dużo wolnej ręki. Te wczesne błędy i halucynacje to dla Ciebie najdroższy feedback – pokazują dokładnie luki w Twojej własnej instrukcji systemowej.
Jak poprawiać błędy? (Zarządzanie zmianami)
Kiedy zauważysz, że AI zachowało się głupio, Twoim pierwszym odruchem może być usunięcie całej instrukcji systemowej i napisanie jej od nowa z poczuciem porażki. To poważny błąd, który tylko cofa Cię w procesie i marnuje włożony wcześniej czas.
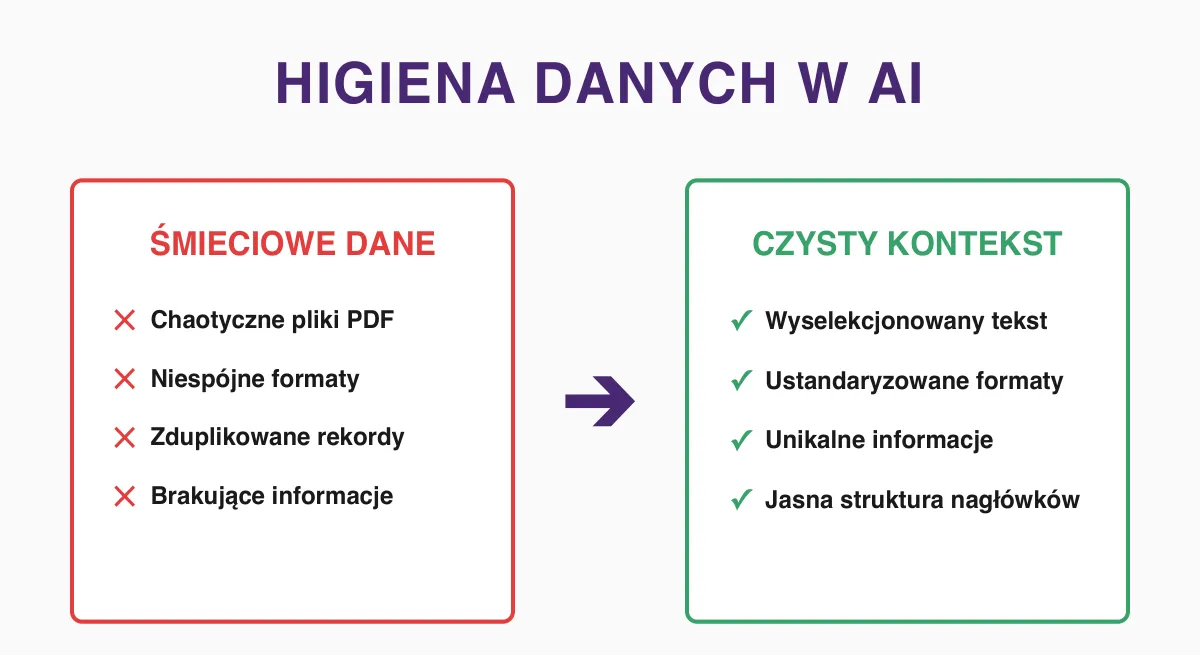
Skuteczne poprawianie asystenta AI polega na punktowym nakładaniu łatek na jego zasady. Jak w rozwijaniu aplikacji czy pisaniu kodu. Poniżej kilka przykładów.
- Błąd asystenta: bot rozciąga notatkę ze spotkania na pięć lanych, nudnych akapitów.
- Twoja łatka: wracasz do edycji instrukcji systemowej i w sekcji „Format wyjściowy” dopisujesz z wielkiej litery: „ZABRANIAM CI pisać podsumowania dłuższego niż 3 konkretne zdania”, albo jeszcze lepiej „NAKAZUJE CI” pisać podsumowania w sposób X.
- Błąd asystenta: Bot używa strasznie korporacyjnego, sztywnego języka przy pisaniu maila.
- Twoja łatka: Wracasz do sekcji „Tożsamość i rola” i dopisujesz na sztywno: „Pod żadnym pozorem nie używaj słów takich jak: kompleksowy, innowacyjny, rewolucyjny. Pisz twardo, zwięźle i bezpośrednio”.
Z każdą taką małą poprawką model coraz mocniej zacieśnia swoje ramy. Po kilkunastu testach i łatkach w końcu dojdziesz do momentu, w którym asystent przestanie popełniać błędy i zacznie przetwarzać dane idealnie powtarzalnie. Wtedy i tylko wtedy możesz uznać budowę za zakończoną.
Krok 5: Kiedy wbudowane narzędzia przestają wystarczać?
Wbudowane ekosystemy typu Custom GPTs, Claude Projects czy Gemini Gems są fenomenalne na start. Dają Ci potężne możliwości weryfikacji danych i automatyzacji żmudnego myślenia przy zerowej znajomości programowania. Jednak w pewnym momencie – zazwyczaj wtedy, gdy Twój asystent staje się kluczowym elementem firmy i zaczyna procesować dane na masową skalę – uderzysz głową w szklany sufit ich zamkniętego środowiska. Głównym problemem wbudowanych asystentów pozostaje to, że wciąż wymagają operatora – musisz ręcznie wkleić im zapytanie i ręcznie skopiować wygenerowany wynik do swojego CRM-a.
Poziom wyżej, czyli CLI i agenty operacyjne (zamiast zwykłych integracji)
Kiedy Twój podstawowy asystent w oknie czatu działa już bezbłędnie, naturalnym krokiem jest szukanie większej skali. Jeszcze chwilę temu standardem było integrowanie takich botów z firmowym krwiobiegiem za pomocą narzędzi no-code (Make, n8n) czy platform typu Dify.
Dzisiaj rynek idzie jednak o krok dalej – w stronę zintegrowanych środowisk i potężnych agentów operacyjnych. Zamiast wyklikiwać skomplikowane ścieżki w n8n, znacznie mocniej opłaca się wejść w narzędzia z poziomu wiersza poleceń (CLI). Mówimy tu o rozwiązaniach typu Claude Code, Antigravity CLI (które w połowie czerwca ostatecznie zastępuje i wygasza dotychczasowe Gemini CLI) czy edytorach pokroju Cursor. To narzędzia, które nie tylko wypluwają tekst w oknie czatu, ale mają bezpośredni dostęp do środowiska, potrafią same odpalić skrypt weryfikujący i zwrócić Ci gotowy, przetworzony wynik.
Jednak zanim rzucisz się na głęboką wodę CLI i zaczniesz delegować pracę zaawansowanym agentom, musisz do bólu opanować fundamenty – czyli logikę budowania bazy wiedzy i tworzenia szczelnej instrukcji systemowej w najprostszych interfejsach.
Zanim wejdziesz w zaawansowany świat środowiska CLI i programowalnych agentów, musisz postawić twarde fundamenty. Przygotowałem 5-dniowy operacyjny kurs mailowy, w którym przeprowadzam Cię dosłownie za rękę przez budowę Twojego pierwszego, biznesowego asystenta krok po kroku. Zero lania wody – dostajesz gotowe struktury i uczysz się omijać rafy, które kładą większość wdrożeń w firmach na samym starcie.
Co z kosztami, czasem i bezpieczeństwem danych?
Na sam koniec zostawiłem trzy kluczowe pytania, które zawsze wracają w głowach decydentów, gdy tylko na stole ląduje temat wdrożenia sztucznej inteligencji.
Czy moje firmowe dane są w ogóle bezpieczne?
To zdecydowanie najczęstsza obawa, jaką słyszę. Krótka odpowiedź brzmi: tak, pod warunkiem, że używasz odpowiednich wersji oprogramowania. Jeśli wrzucisz cennik firmy do darmowego, publicznego ChatGPT – ryzykujesz, że te dane posłużą do trenowania ogólnego modelu. Jeśli jednak korzystasz z zamkniętych, płatnych środowisk biznesowych (jak ChatGPT Team/Enterprise, subskrypcje Claude Pro lub bezpośrednia integracja przez API), dostawcy jasno gwarantują w umowach, że Twoje pliki i prompty nie karmią zewnętrznych algorytmów. Na ile im wierzymy to już nie moja sprawa.
Ile to fizycznie kosztuje w 2026 roku?
Zbudowanie świetnego, podstawowego asystenta (np. w Custom GPTs) kosztuje wyłącznie Twój czas plus standardowy abonament za samo narzędzie (czyli około 20-30 dolarów miesięcznie). Nie płacisz prowizji zewnętrznym programistom za stworzenie AI. Jeśli pójdziesz poziom wyżej i wejdziesz w integracje po API z własnym systemem (np. przez n8n), płacisz mikroskopijne ułamki centów za każdy wygenerowany „token” (czyli fragment słowa). Koszty operacyjne takiego wirtualnego asystenta, który codziennie weryfikuje dziesiątki zapytań, zamykają się zazwyczaj w kilkudziesięciu złotych na miesiąc.
Ile czasu zajmie mi wdrożenie pierwszego bota?
Samo „wyklikanie” pierwszego asystenta i wklejenie mu instrukcji systemowej w gotowym panelu to praca na kwadrans. Prawdziwą walutą, którą musisz tutaj zainwestować, jest czas spędzony na ręcznym wyczyszczeniu bazy wiedzy (plików tekstowych) oraz na procesie nakładania poprawek w fazie testowej. Realnie patrząc, dobrze zoptymalizowany, prosty asystent operacyjny do sprawdzania danych jest w pełni gotowy do regularnej pracy w firmie po około 2-3 dniach rzetelnego testowania.




